

Modern GTM teams are not losing to data scarcity, they are losing to a failure of B2B data prioritization. The average sales team now has access to 12.7 data sources per account and 47 individual data points per prospect. Cold outbound conversion rates remain at 2.3%, while time-to-close has increased 18% over two years. More data is not producing better decisions. It is producing slower ones.
Data does not make for better decisions; data makes for slower decisions.
A 2024 audit on 40 revenue GTM teams found that 68% of data points in CRMs remained unused for routing, sequencing, or scoring decisions. 82% of enrichment fields were used only for display, never for decision-making. 41% of intent-driven campaigns did not adjust their cadence, content, or offer based on the intent signals they purchased. Organizations are collecting data they never act on, and treating the data they do act on as if every signal carries equal weight.
That assumption, that all data matters equally, is one of the most expensive operational errors in modern B2B go-to-market design.
What B2B Data Prioritization Actually Means & Why It’s a Revenue Question
B2B data prioritization is not a data quality effort. It is a revenue design question.
A field or signal is high priority not based on its cleanliness or completeness, but rather if it makes a GTM decision better, correlates with pipeline results, and impacts behavior measurably. And by that definition, very little of what populates a CRM would fit.
An effective operational model breaks down data into three categories:
Critical data directly predicts conversion probability or accelerates deal velocity. This includes verified buying intent signals, budget authority indicators, active technology evaluations, organizational triggers such as funding events or leadership changes, and decision-maker contact accuracy. When these signals disappear, pipeline degrades. They deserve immediate enrichment, real-time validation, and primary placement in every workflow.
Secondary data provides context and supports personalization but does not independently trigger action. Industry vertical, company size, historical engagement patterns, and secondary technographic layers all belong here. They improve outreach quality once Tier 1 data has confirmed an opportunity is worth pursuing. They should inform messaging, not prioritization sequencing.
Low-value data has weak or zero correlation with conversion in your specific sales model. Outdated firmographics, bulk contact scrapes, generic website visit history, and intent topics misaligned with your product category fall into this tier. Closed-won regression analysis is the clearest diagnostic: any field appearing in fewer than 15% of won deals with no measurable velocity impact should be deprioritized or retired.
The distinction between these tiers is not academic. One SaaS company tracked data consumption across their SDR team and found that reps reviewed an average of 23 fields per prospect during research. Closed-won analysis showed only 6 of those fields correlated with conversion. Across 1,200 monthly outreach targets, the 17 irrelevant fields cost 78 hours of productive selling time per month.
Why B2B Data Prioritization Fails: Three Structural GTM Breakdowns
Three structural failures prevent B2B data prioritization from taking hold in most organizations.
The first is volume without filtering. A 2024 benchmark study, by Syncari, of 90 B2B GTM stacks found the median team maintained 72 data fields per account, integrated 12 external data sources into CRM or a CDP, and ran 8 or more scoring or segmentation layers. Enrichment APIs add another 15-20 attributes automatically, with no built-in mechanism to filter by revenue relevance. When teams are overwhelmed, they fall back to defaults: relying on a single composite score without understanding which signals drive it, or building sequences on arbitrary “enriched accounts” lists that treat every record as equally actionable.
The second failure is the absence of prioritization frameworks. Most organizations categorize data by source or type rather than business impact. CRM fields display alphabetically or by creation date. Without a formal taxonomy of critical versus secondary versus low-value data, decisions about what to track and act on are made ad hoc. One demand generation manager described the problem directly: “Our enrichment workflow triggered on 18 data points. Marketing automation scored leads using 12 attributes. But pipeline regression showed only 4 fields mattered: employee headcount, technology stack category, funding stage, and intent topic strength. We were enriching 78% unnecessary data at $0.40 per API call.”
The third failure is strategic misalignment. A cybersecurity vendor purchased an intent data platform tracking over 400 topics, then routed every account showing any intent signal to sales. SDRs received leads researching “what is endpoint protection” alongside accounts actively evaluating vendors. Of 2,800 monthly intent-flagged accounts, only 47 became qualified opportunities, a 1.7% conversion rate. The platform cost $78,000 annually. Effective cost per qualified intent lead: $1,660. The problem was not the data. It was the absence of prioritization logic distinguishing genuine evaluation signals from low-value educational research.
The Volume-vs-Accuracy Trade-Off: Why More Signals Undermine GTM Data Prioritization
One of the most consequential misconceptions in B2B intelligence is that broader coverage improves outcomes. It often does the opposite.
Volume-centric data strategies attempt to possess a record for every account in a market. The result is high data decay, diluted accuracy, and signal overload. A database that is 90% complete but architecturally flat, where a funding alert carries the same weight as a LinkedIn page view, produces less actionable intelligence than a smaller, validated dataset of genuinely in-market accounts.
The trade-off is illustrated best in intent data. Without any filters, when intent signals are directed toward the sales department, the conversion rates are drastically affected by volume. You can read more here.
A martech platform that had been using Bombora had been directing 400 intent flagged leads each month to the SDR department. However, after introducing topic relevance scoring and surge intensity filters, only 80 leads were qualified to be contacted right away. The conversion rates shot up from 3.1% to 11.8%.
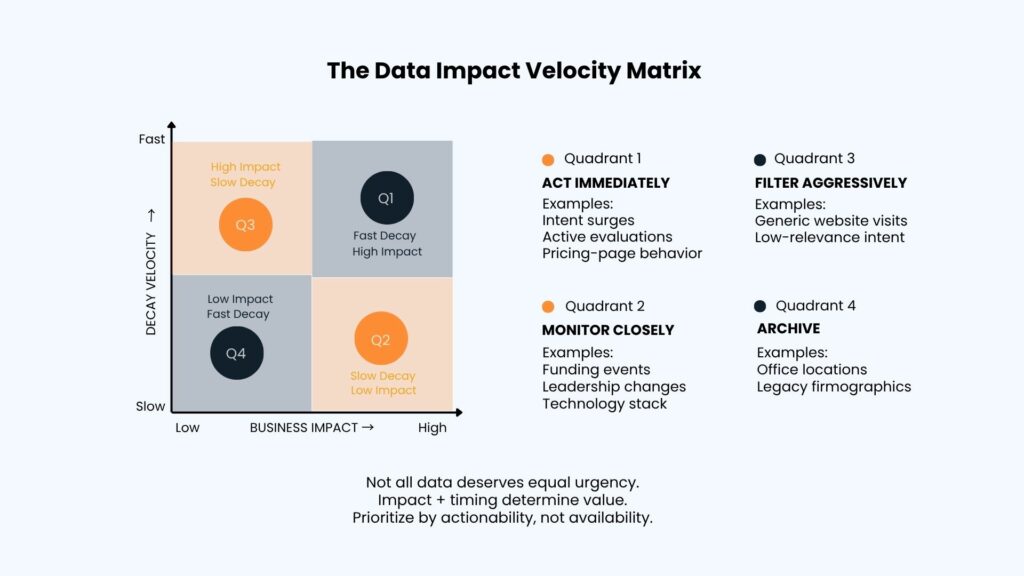
The Data Impact Velocity Matrix, a framework for evaluating incoming signals along two dimensions, business impact factor and decay velocity, formalizes this logic. Direct contact points such as verified direct-dials and corporate emails score high on both dimensions: they are critical for conversion and decay at roughly 30% annually as professionals change roles. Active intent signals score highest on decay velocity, with a buying window of two to six weeks, making immediate routing essential. Firmographic data decays slowly and warrants only quarterly or biannual batch enrichment. Generic context data, such as aggregate office locations or company news feeds, adds minimal value and should be suppressed from primary execution systems entirely.
A Revenue-Aligned B2B Data Prioritization Framework
Effective B2B data prioritization requires a scoring model that connects data attributes to revenue outcomes rather than data availability.
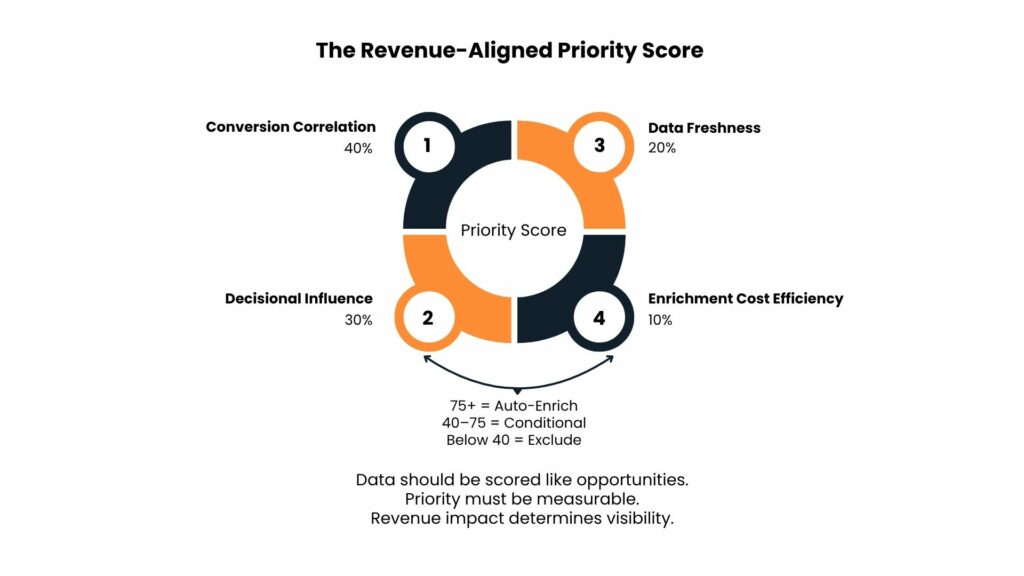
The Priority Score formula weights four components: conversion correlation (40%), decisional influence (30%), data freshness (20%), and enrichment cost efficiency (10%). Conversion correlation measures the statistical relationship between attribute presence and closed-won status. Decisional influence captures how frequently the attribute appears in qualify or disqualify decisions, measured through CRM workflow analysis. Data freshness scores recency inversely, with a 90-day refresh scoring 1.0 and data over 365 days old scoring 0.2. Enrichment cost efficiency captures revenue generated per dollar spent acquiring that data point.
Attributes scoring above 75 receive automatic enrichment and primary CRM visibility. Scores between 40 and 75 enrich conditionally based on account fit. Below 40: exclude from standard workflows.
This process was adopted by another software company, which found out that “active job postings” had been classified under Tier 1 because of its high correlation with growth and purchasing power potential. However, the quarterly assessment showed that correlation levels went down from 0.68 to 0.34 because of the effects of hiring freezes on the target market population. Consequently, job postings were re-classified under Tier 2 and the company shifted its focus to changing the technology stack that now correlated at 0.71.
Operationalizing B2B Data Prioritization: Four Mechanisms That Drive Pipeline
Tiered enrichment workflows replace universal enrichment with conditional logic. High-fit accounts with strong ICP match and buying signals trigger comprehensive enrichment across all Tier 1 and Tier 2 fields. Medium-fit accounts enrich Tier 1 only. Low-fit accounts receive minimal enrichment sufficient for disqualification confirmation. A healthcare IT company applied this approach across 1,400 monthly leads. Previous universal enrichment cost $3,920 per month. Tiered enrichment cost $2,156, a savings of $1,764 monthly, while improving data relevance for the accounts that actually mattered.
CRM field prioritization restructures how information is surfaced to sales reps. A primary view displays only Tier 1 data, six to eight fields, and serves as the default. Secondary views add contextual fields. Complete views include everything but require deliberate access. One implementation reduced average CRM page load time by 40% and increased Tier 1 data review rates by 63%, measured through field-click tracking in Salesforce analytics.
Intent signal filtering applies topic relevance scoring and surge-intensity thresholds to separate genuine evaluation activity from low-value research behavior. High-priority intent routes to immediate SDR follow-up. Medium-priority feeds nurture campaigns. Low-priority intent remains in the database but triggers no workflow action. This filtering, not intent data quality, is what determines whether intent platforms deliver pipeline.
Prioritization calibration on a continuous basis is performed using closed-won analysis at a quarterly rate, focusing on those attributes that recur most often in winning opportunities and those that have lost relevance due to changes in the market environment. Data significance is dynamic; attributes that contribute to conversions today can cease to be relevant tomorrow.
Practical Recommendations for RevOps Leaders
Run a data-relevance audit before investing further in enrichment, this is the foundation of any B2B data prioritization effort. List every data source, field, and signal your GTM systems consume. Calculate a relevance score for each using impact on pipeline, usage rate across routing and sequencing workflows, and statistical predictive power. Any field that has not driven a routing or sequencing decision in 90 days is not Tier 1.
Reduce data overload by deprecating low-value fields in execution systems. One organization reduced their enrichment map from 87 fields to 18 core decision-driving fields. Pipeline and velocity held flat. Data maintenance overhead dropped by 40%. Less active data is not less intelligence. It is cleaner execution.
Map each Tier 1 signal to a specific GTM action. A funding alert should trigger SDR outreach within 24 hours. A decision-maker job change should route to account-specific sequencing. An active pricing page visit should elevate an account’s intent score above the workflow threshold. If a signal cannot be mapped to a specific action with a measurable expected outcome, it is not Tier 1.
Build workflows around four to eight high-value fields rather than comprehensive data sets. One RevOps team found that using only four prioritized firmographic and intent fields in routing increased pipeline from high-value accounts by 23%, while fields kept for display only with no routing logic had no measurable impact.
Review priority areas on a quarterly basis. With changes in GTM strategy, there is a need to shift priorities. Have quarterly review sessions to ensure asset recategorization, reweighting of signals, and obsolescence of uncorrelated data fields.
Conclusion: Revenue Belongs to the Focused, Not the Comprehensive
The competitive edge in B2B intelligence is not moving toward organizations with the most data. It is moving toward organizations with the clearest understanding of which data drives decisions and which data consumes attention.
Implementing B2B data prioritization typically improves research efficiency by 30-45%, reduces enrichment costs by 25 to 40%, and increases conversion rates by 15 to 30% by concentrating sales capacity on genuine buying signals. These are not marginal gains. They are the operational difference between a GTM system that compounds efficiency and one that compounds complexity.
Not all data deserves equal attention. Most data deserves none at all. The organizations that outperform will not be those that collected the most signals. They will be those that built the discipline to know which signals to act on, which to archive, and which to stop buying entirely.






























