When the VP of Sales questions the pipeline forecast three hours before the board meeting, the problem isn’t data scarcity; it’s data credibility. This is the core challenge that data trust architecture is designed to solve. Modern B2B organizations run CRMs, enrichment platforms, intent providers, attribution tools, and AI-driven scoring engines in parallel. Yet a 2025 survey of 72 revenue-focused companies found that 68% of executives and 59% of RevOps leaders regularly questioned the accuracy of their core dashboards. That is not a volume problem. That is a data trust collapse.
According to OneStream, 72% of companies say bad data costs them at least $500,000, and more than one-third report losses over $1 million. A mid-market B2B firm, with $50 million in yearly income, actually loses around $1.25 million each quarter for every week their strategic decisions are held up because of data issues. The future competitive advantage in B2B intelligence belongs to organizations with the most trusted data systems, not the largest ones.
Why Data Trust Breaks in Revenue Organizations
Data trust rarely collapses from a single failure. It erodes through four compounding structural problems.
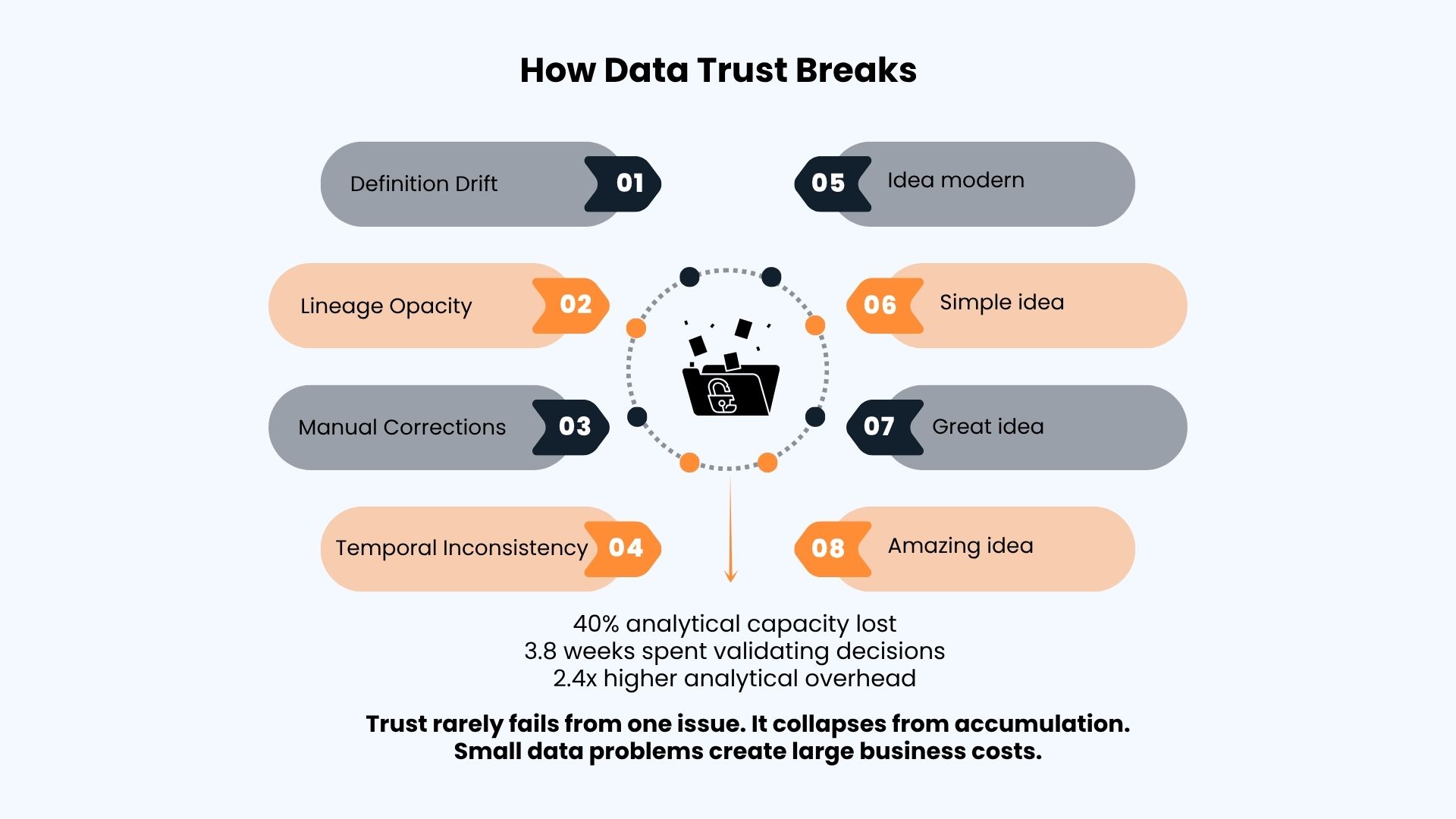
Definition Drift and Lineage Opacity
Definition drift is the most common fracture point. Marketing counts an “active account” using website intent signals. Sales counts it only after a validated opportunity exists in the pipeline. Finance recognizes it after the first invoice clears. A 2024 analysis of 200 B2B organizations found an average of 4.7 conflicting definitions for core metrics across departments. One SaaS company discovered a 23% discrepancy between marketing and sales pipeline numbers that stalled a market expansion decision for six weeks. RevOps teams in low-definition environments waste an estimated 40% of their analytical capacity reconciling conflicts rather than generating actionable insight.
Lineage opacity compounds the damage. Modern B2B data architectures pass through 7 to 12 transformation layers between source systems and executive dashboards. A 2025 RevOps survey found that only 19% of teams could reliably trace 90% of core revenue metrics back to their source. A telecommunications B2B provider traced an 18% variance in customer lifetime value calculations through five transformation layers to a JOIN operation excluding multi-product customers. The error had misdirected $4.2 million in R&D resources over eight months. Without lineage, debugging is archaeology.
Manual Corrections and Temporal Inconsistency
Undocumented manual corrections are equally destructive. In 68% of B2B organizations studied, finance teams make manual adjustments to revenue data that are never logged in audit-accessible formats. One manufacturing company’s monthly reporting incorporated 127 undocumented Excel adjustments maintained by three analysts. When two departed within six weeks, month-end close extended from four days to nineteen days while the team reverse-engineered the correction logic.
Temporal inconsistency in snapshot data creates a subtler but equally costly problem. When March pipeline forecasts use February 15 data but the comparison baseline uses February 28 data, the 13-day delta introduces noise that masquerades as signal. A private equity firm discovered their month-over-month growth calculations compared snapshots across different billing cycles, causing three portfolio companies to be systematically underfunded.
The Compounding Revenue Cost of Low Data Trust
Low data trust does not just slow decisions. It restructures how organizations operate, creating cascading costs that function as a hidden tax on the entire revenue pipeline.
Analytical duplication alone is substantial. A 2024 RevOps case study found an organization spending 11,000 analyst hours per year reconciling data that should have been settled once. Organizations with low data trust spend 2.4 times more on analytical headcount relative to revenue than high-trust peers.
Tool adoption collapses in low-trust environments. Enterprise analytics implementations average $2.8 million in first-year costs. When users continue relying on legacy spreadsheets, adoption stalls near 40%, tripling the effective cost per active user. A 2025 benchmark of 50 revenue teams found that 63% of SDRs and AEs used spreadsheets as their primary source for account prioritization, not the company-wide BI system.
The speed penalty is measurable. The median B2B company takes 6.2 weeks to agree on big decisions, and it spends 3.8 weeks just verifying data. Companies with low trust in their data take 31% longer to wrap up their plans. On the flip side, rivals who trust their data cut their decision-making time by 60%, gaining first-mover benefits that stack up in every cycle.
The LIVE Framework: Four Pillars of Data Trust Architecture
Building a reliable data trust architecture requires four foundational capabilities that work together.
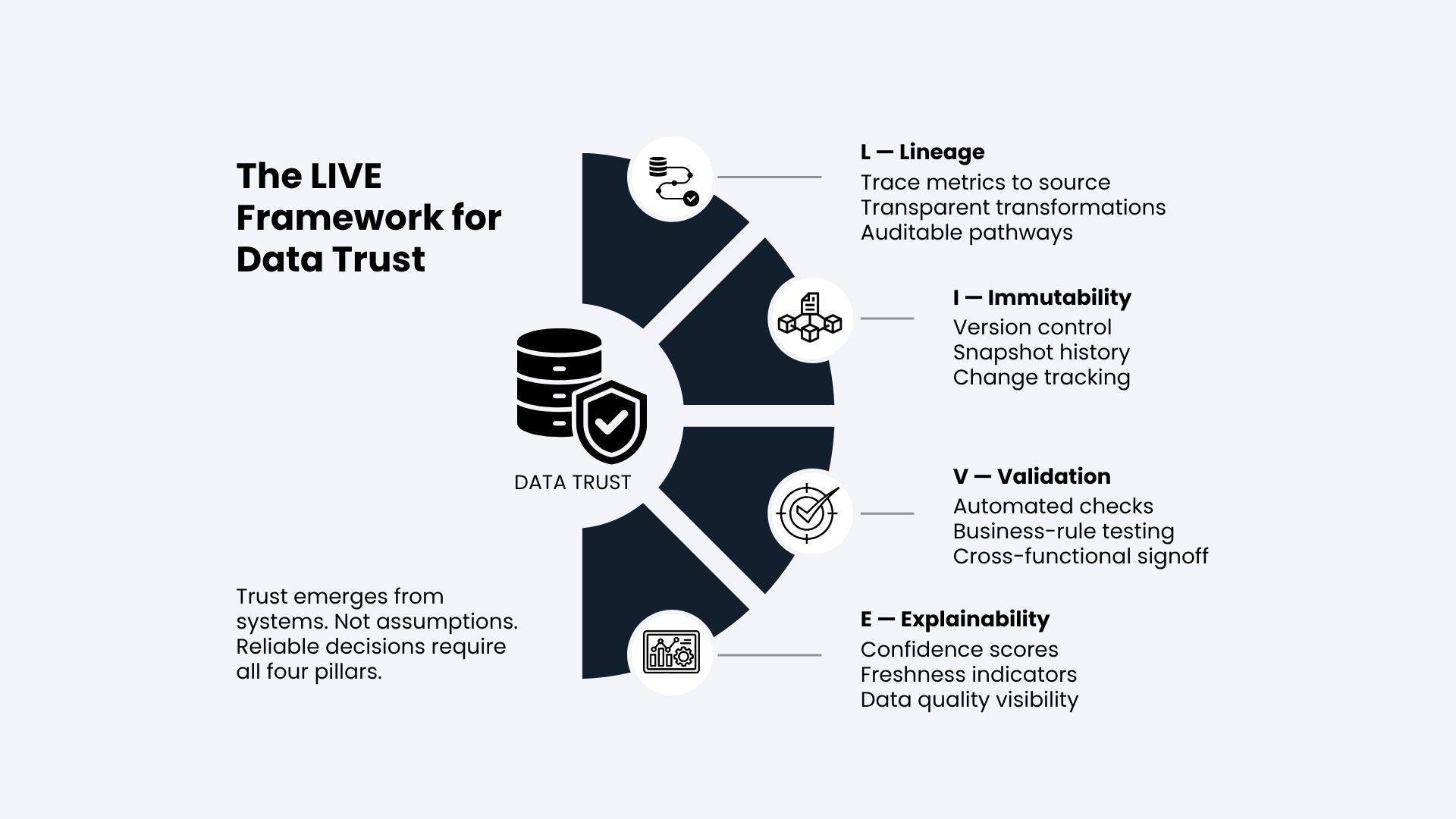
Lineage means every metric traces back to its source through documented, auditable pathways visible to business stakeholders, not just data engineers. Column-level lineage implementation at one enterprise software company reduced analyst time spent on “where does this number come from” investigations by 73%.
Making datasets immutable is about treating them like code. This means versioning each transformation, taking snapshots at key decision points, and keeping logs of changes and reasons why those changes happened. Take a B2B logistics firm; after they started versioning their datasets, they reduced their monthly discrepancy solving time from 40 hours to just 7 hours. That’s huge!
For validation, you need checks across different levels. Start with checksums in the source system to make sure the data warehouse is accurate. Add automated business rule tests for logic checks before report publishing. Also, include cross-departmental approval steps where finance and sales teams must sign off on figures together. At a manufacturing company, a similar setup caught a currency conversion mistake in cost calculations that had gone unnoticed for 14 long months. With the new validation process, they spotted it right on day one.
Explainability means showing confidence levels right in dashboards. Including data freshness, completeness scores, and source quality ratings gives stakeholders the context needed to properly interpret the metrics. One SaaS company added confidence scoring and saw executive engagement with analytics dashboards rise 45%, as leaders got more visibility into data limitations.
You can read more about building a composable data architecture here.
A Practical Evaluation Tool: The Data Trust Scorecard
A practical way to audit your data trust architecture is the RevOps Scorecard. RevOps leaders can use a Data Trust Scorecard to measure trust in core revenue metrics. This scorecard rates each metric on four things from 0 to 5.
First, Lineage Transparency: Can we trace the metric to its origin?
Second, Governance and Process: Does paperwork exist for changes and have people been told about them?
Third, Definition Clarity: Has everyone agreed to one definition?
Fourth, Adoption and Reliance: Do stakeholders make calls based on the metric or do they secretly use other spreadsheets?
The Trust Score is the average of those four parts. When used in a 2025 RevOps study, it cut data-checking delays by 28% and boosted analytics adoption by 19%, all within a year and a half.
Practical Recommendations for RevOps Leaders
Audit trust failures directly. Map where stakeholders distrust systems, which dashboards face the most scrutiny, and where manual verification recurs. Trust friction reveals the weak points that accuracy metrics alone cannot surface.
Create a shared metric glossary for the most crucial GTM metrics. Include the definition, source system, key rules, owner, and change history for each one. Show this to everyone, and make it a requirement to review it before getting access to the executive dashboard.
Build cross-functional data governance. Form a working group with representatives from RevOps, sales operations, marketing operations, and finance. Define change-control processes and require that all substantive changes are communicated before they affect operational reporting. Organizations with complete alignment between finance and IT are 5.5 times more likely to report full confidence in their data.
Monitor continuously. Set service-level indicators for key revenue metrics, automate freshness and anomaly checks, and treat data quality like application performance. Catching structural errors in real time prevents downstream sales impact before it registers in the pipeline.
Reliable Data Is the Actual Competitive Advantage
Data volume is no longer the differentiator. Most B2B companies already have way more data than they know what to do with. The big issue isn’t about having enough data; it’s whether the people making decisions trust that data enough to actually use it.
The organizations that thrive are the ones that invest in data trust architecture treat trust as infrastructure, not a by-product. Every measurement needs to be clearly defined and understood by everyone involved. When you treat trust as something concrete and build systems around it, teams start seeing how reliable their data is right in their workflow. This means no more wasting time; like 3.8 weeks per quarter just checking numbers, are needed before moving forward.
The organizations that will lead in the next phase of B2B intelligence are not those collecting the most signals. They are those who have built the infrastructure to verify, govern, and confidently activate the data they already have.
Reliable data is not a luxury. It is the foundation for every strategic advantage that follows.