

Most data systems don’t fail at launch. They fail when they succeed; a fundamental data scalability architecture problem.
The CRM enrichment process that works seamlessly on 10,000 records fails on 100,000 records. The marketing automation system working perfectly with 200 leads every week fails once there is a campaign generating 2,000 leads. The system remains the same but its volume changes.
Based on Gartner’s findings from 2023, 47% of all data systems suffer from reduced functionality at a mere 3x the scale of their initial capacity. When it comes to RevOps, it results in inaccurate pipeline analysis, outdated intent scores, and SDRs reporting that contact information is lacking. The problem is not necessarily downtime; the issue is a slow degradation of trust in the accuracy of your data.
Understanding Data Scalability Architecture: Three Core Dimensions
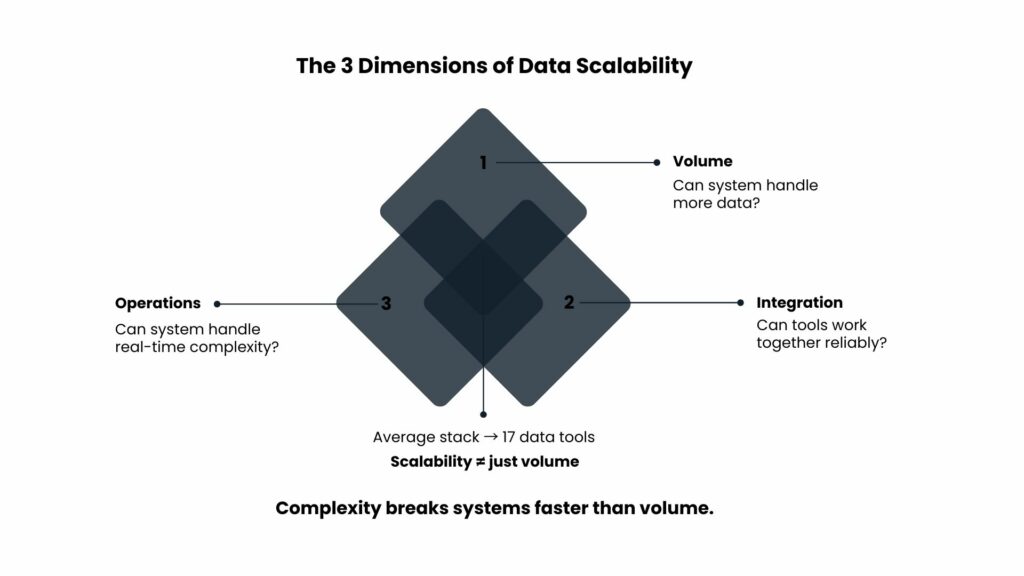
Data scalability architecture encompasses three distinct dimensions that organizations often conflate when planning for growth.
Volume scalability focuses on pure throughput. Are you able to support 50,000 API enrichment requests per day compared to 5,000? But volume scalability alone doesn’t account for complexity. A system that handles 100,000 basic contacts may fail once you need to merge 10,000 records using multiple data sources, implementing deduplication and resolving conflicts with third-party APIs.
The need for integration of scalability increases as your infrastructure grows. Connecting three platforms such as Salesforce, HubSpot, and one enrichment tool can work just fine. Once you throw in Outreach, Gong, ZoomInfo, Clearbit, and a data warehouse, you have built an ecosystem of interdependencies, where a failure of one service affects all the others. On average, a B2B business uses 17 data tools, according to the ChiefMartec 2024 research.
Operational scalability is defined by the capability of your system to retain reliability amid varied usage patterns. For a startup, batch enrichment may be performed on a weekly basis. As for the growth phase, real-time enrichment is necessary on account of form submissions, chats, and integrations that must happen in parallel. According to Databricks’ research, 62% of failures in data pipelines result from such interactions, not volume.
Where Scalability Failures Manifest
Degradation of processing usually starts slowly but reaches a point where the increase becomes dramatic. If a data enrichment pipeline takes two minutes initially, doubling the number of records makes it take five minutes. Increasing by an additional twenty percent causes processing times to balloon up to forty-five minutes and leads to timeouts, job failures, and partial data sets. This is due to the nature of most processing systems having certain tipping points: queries becoming inefficient, rate limiting of APIs, memory exhaustion, and network limits.
Let’s consider a practical example. A Series B SaaS company that ran nightly enrichment pipelines extracting company data from three different providers, combining them, and then updating Salesforce found its enrichment process took forty minutes for five thousand accounts but three hours for fifteen thousand accounts. At 25,000 accounts, it failed entirely. Not because servers crashed, but because sequential API calls, conflict resolution logic, and Salesforce update operations couldn’t complete before the next batch started. The system wasn’t designed for scale. It was designed to work. This failure illustrates why data scalability architecture must be designed upfront, not retrofitted after systems break.
System overload creates downstream effects beyond slow processing. When enrichment services lag, sales teams start manually researching accounts, creating duplicate records, inconsistent data formatting, and bypassing validation rules. Salesforce reports from 2023 indicate that 34% of CRM data quality issues originate from workarounds created when automated systems fail to perform.
Integration failures multiply as systems scale because they operate on different assumptions. Your CRM expects responses within 10 seconds. Your enrichment provider’s SLA allows 30 seconds. At low volume, average response time stays under threshold. At scale, the provider’s 95th percentile response time exceeds your timeout, causing intermittent failures that are difficult to diagnose and impossible to prevent without architectural changes.
You can read more about this, here.
The Revenue Cost of Weak Data Scalability Systems
The cost of scaling failures extends beyond engineering resources. LinkedIn’s B2B Institute research found that sales teams using incomplete or stale data experience 27% longer sales cycles and 18% lower win rates. But the compounding effect is more severe.
When a successful campaign generates 800 leads in one day instead of the usual 100, the enrichment backlog grows to 3 days. By the time intent data is available, those signals are stale. The prospect who showed buying intent on Monday receives outreach on Thursday after they’ve already engaged with a competitor. The revenue impact isn’t from system failure. It’s from timing degradation that makes accurate data useless.
Pipeline visibility suffers disproportionately. The RevOps team requires comprehensive data to forecast, plan territories, and allocate resources. If the enrichment tools cannot match the amount of data being collected, then reporting is inaccurate. Based on the Forrester 2024 B2B Data Quality research study, “41 percent of revenue professionals said they made strategic decisions using incomplete data during periods of growth.”
The Scalability Design Framework
Effective data scalability architecture requires design decisions made before scaling pressure appears. The Throughput-Consistency-Latency triangle provides a decision framework.
Throughput measures volume capacity. How many enrichment operations per hour can your system handle? Increasing throughput typically requires parallel processing, which introduces consistency challenges. If three enrichment providers return conflicting company revenue data for the same account, which source wins? Sequential processing makes this decision straightforward. Parallel processing requires conflict resolution logic designed upfront.
Consistency ensures data accuracy across integrations. Eventual consistency, where different systems show different data temporarily, might be acceptable for some use cases but catastrophic for others. A sales rep viewing account data in Salesforce while a marketing automation system sends an email based on slightly different data creates customer experience issues.
Latency defines how quickly data must be available. Real-time enrichment requires fundamentally different architecture than batch processing. Organizations often demand real-time performance without considering the cost. Real-time systems need redundancy, caching layers, and fallback mechanisms that batch systems don’t require.
The strategic choice isn’t optimizing all three. It’s deciding which two matter most for your use case and architecting accordingly. High-volume lead enrichment might prioritize throughput and latency, accepting eventual consistency. Strategic account intelligence might prioritize consistency and latency, processing lower volumes with higher quality standards.
Building Modular Data Scalability Architecture
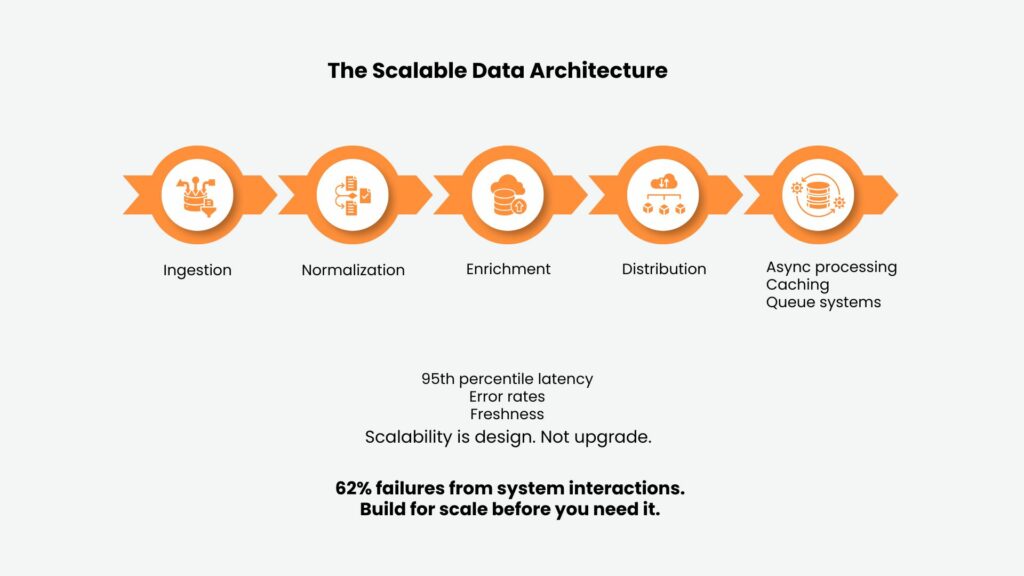
A robust data scalability architecture segregates functionality into independent yet loosely coupled modules. The architecture should avoid using a single big-enrichment model but rather employ an independent module-based approach that allows each transformation to run independently.
The initial stage will involve the creation of an ingestion module. Another stage will be to introduce a normalization module to standardize data. The third stage involves enriching data using another data module. Finally, the fourth stage entails distribution through yet another module. Scaling will depend on bottleneck analysis.
Asynchronous processing decouples data collection from enrichment from distribution. When a new lead enters your system, the immediate response confirms receipt. Enrichment happens separately. This prevents user-facing processes from slowing as backend operations scale. The trade-off is added complexity. You need queue management, retry logic, and monitoring to ensure eventual processing.
Caching strategies dramatically improve scalability for repetitive queries. If fifty sales reps view the same strategic account daily, enriching that account once and caching results for 24 hours reduces load by 98%. But caching introduces staleness. You’re explicitly choosing to show slightly outdated data for performance gains.
Implementing Data Scalability Architecture: Protection Strategies
Scalability protections need to be in place even before there is a failure.
Rate limiting and back pressure controls ensure that upstream services do not overload downstream services. For instance, if your enricher API supports 1,000 requests per minute, your ingestion system needs to limit itself to 800 requests per minute, which will provide room for spikes. Data prioritization tiers ensure critical operations scale first. Not all enrichment is equally valuable. A $500K enterprise opportunity needs immediate, complete enrichment. A $5K SMB lead can wait in the queue. Prioritization tiers allow avoiding the blocking of high-priority work by low-priority and large-volume tasks.
The choice of appropriate performance indicators is crucial. The average processing duration is almost meaningless, as it does not reveal anything about variability. In contrast, the 95th percentile of latencies – those slowest 5% – predict user dissatisfaction better. It’s critical to care about error rates, not uptime; in terms of actual service, when a system fails 15% of the time, it’s down anyway.
Conclusion: Scalability as Strategic Design
Data scalability isn’t a problem to solve after systems break. It’s an architectural decision made during initial design. The systems that survive 10x growth aren’t necessarily better engineered. They’re designed with different assumptions. They anticipate multiple integration points, plan for variable latency, and separate concerns into independently scalable components.
For RevOps leaders, the insight is all about timing. Investing in scalability before growth happens is exponentially more cost-effective than investing during the crisis. As far as tactics go, the insight here is measuring the right things. You’d be crazy not to measure 95th-percentile latency, error rates, and data freshness.
Data systems that fail under load weren’t necessarily built badly. They were built under different assumptions. This means that the question you have to ask yourself isn’t, “Can your current architecture scale?”, but “What did you plan for when it didn’t?”















