

Dashboards are green, pipelines are working, and alerts are silent. But at the same time, you’re spending valuable time chasing down non-existent accounts, your SDRs’ days are wasted reaching out to bad leads, and your forecast accuracy rate has gone down by 41%. This is a case of invisible data corruption. It happens quietly and costs businesses an estimated $12.9 million per year. Data corruption is one of the main reasons why almost 42% of enterprises stated that more than half of their AI initiatives were postponed or failed, according to a survey conducted in 2025 among 401 data leaders.
Most organizations monitor infrastructure religiously. They track CPU usage, memory consumption, and API response times. But they do not monitor their data, the actual asset driving decisions. This is the data observability gap, and for revenue operations teams managing seven and eight-figure pipelines, it represents an invisible tax on every strategic choice.
What Data Observability Measures (And Why the Gap Exists)
Data observability extends beyond traditional system monitoring. It answers not “Is the system running?” but “Is the system producing reliable outputs?”
The distinction matters. A CRM sync might complete successfully while dropping 15% of contact updates. An enrichment job processes on schedule but only covers 60% of records due to API limits. Intent signals arrive with 72-hour delays. No errors trigger. No alerts fire. The damage compounds silently.

The Five Critical Dimensions of Data Observability Gap
Freshness measures how recent data is and whether updates arrive on time. In B2B, an intent signal loses value rapidly. If latency jumps from 5 minutes to 5 hours, the data has failed even if the pipeline succeeded.
Volume tracks whether expected amounts of data flow through systems. A sudden spike or flatline typically indicates broken tracking pixels or failed API integrations. A daily enrichment job that processes 40% fewer records than baseline has failed, regardless of technical completion status.
Distribution catches problems that do not violate rules but distort reality. If 35% of your pipeline typically comes from enterprise accounts and suddenly shifts to 55%, you face either a market breakthrough or a segmentation failure. When email open rates jump 40% overnight, you probably have a tracking implementation break, not an engagement miracle.
Schema monitors structural integrity. When the “Industry” field starts receiving job titles, your schema has drifted. When a data provider shifts existing values from a “size” field to “legacy_size” without notification, your segmentation rules execute against empty fields. No errors appear. Your ICP targeting just stops working.
Lineage provides the audit trail from source to dashboard. When conversion rates look wrong, lineage allows you to trace back through transformations to find exactly where logic failed. According to SiriusDecisions research, 25% of B2B organizations cannot trace how their lead scores are calculated, making silent failures nearly impossible to diagnose.
Four Data Observability Failures Hiding in Revenue Pipelines
Revenue teams operate with broken data longer than they realize because observability gaps manifest in ways that evade standard monitoring. Each of the following failure modes is a direct symptom of the data observability gap.
Silent schema drift occurs when upstream systems change structures without notification. A data provider modifies their taxonomy, now categorizing directors as “management” instead of “leadership.” Your lead scoring model continues executing perfectly. Results become meaningless. Detection happens quarters later when reviewing win rates by segment.
Gradual decay masquerading as variance presents as normal fluctuation. Email bounce rates creep from 3% to 11% over eight months. Each week feels within range. No single day trips an alert. But the cumulative impact; thousands of unreachable prospects, declining sender reputation, contaminated lists, represents material revenue leakage with no definitive break moment.
Transformation logic failures emerge when business rules and data reality diverge. Marketing automation shows 450 MQLs this quarter. CRM reports 520. Your data warehouse calculates 475. Each system is internally consistent. Each team defends their number. Revenue forecasts built on any of them are equally wrong, but no error appears in any log.
Cross-system inconsistency creates multiple versions of truth. One enterprise SaaS company discovered their entire Q3 demand generation budget targeted accounts using an enrichment feed that had not updated industry classifications in 14 months. Their “high-growth fintech” segment was actually legacy financial services companies that had since pivoted or been acquired.
The Revenue Cost of the Data Observability Gap
The business cost of the data observability gap concentrates in three areas.
Pipeline inefficiency manifests when teams operate on degraded data. If 20% of contact information is outdated and systems cannot flag which 20%, reps either waste time on dead ends or spend resources re-verifying everything. Salesforce’s 2023 State of Sales report found that reps spend 72% of their week on non-selling activities, with data quality issues consuming the largest share. For a 50-person sales team, a 10% reduction in selling time from bad data represents roughly $2.1 million in lost productivity annually.
Misallocated GTM spend occurs when targeting relies on corrupted signals. Intent data with 48-hour latency gets treated as real-time, causing marketing to engage prospects after buying windows close. Firmographic data with 35% accuracy drives ABM campaigns to wrong personas.
Delayed problem detection compounds every other failure. The leader of revenue operations in a Series C firm found that they were using inaccurate information to make important business decisions due to an error in their pipeline reports, which had been going on for five months without the team’s knowledge. Deals that got synced from Salesforce to the warehouse were somehow getting filtered out of the report depending on where they stood in the pipeline process.
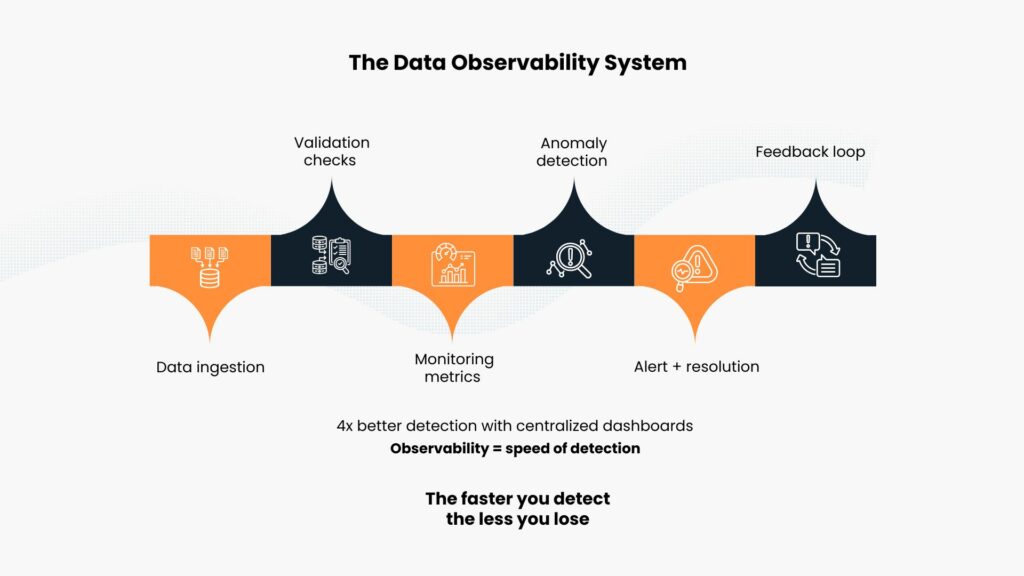
How to Close the Data Observability Gap: 5 Operational Steps
Implementation requires structured measurement across the data lifecycle.
Define data health metrics explicitly. Do not rely on implicit assumptions. Set tolerable fill rates, freshness levels, and accuracy standards for mission-critical resources. A contact record fit for newsletter segmentation might not suffice for sales campaigns. Measure data quality on factors that count: completeness of the fields needed for engagement, freshness of enrichments (job title updated within 90 days), credibility of signals (intent scores with proven accuracy >70%).
Implement automated anomaly detection. Track expected distributions and trigger alerts when patterns shift. If firmographic coverage typically holds at 90% and drops to 65%, high-value accounts are being excluded from campaigns. Manual checks do not scale. Deploy statistical or machine learning-based detection for volume, freshness, and distribution anomalies.
Create centralized visibility dashboards. These are not engineering dashboards showing server metrics. Such metrics include:
“Freshness of contact information for Q1 target customers: 78% refreshed within 30 days” or
“Latency of intent signal: Median 8 hours, 95th percentile 26 hours.”
Firms having unified dashboards measuring data health have a fourfold higher ability to detect problems than those that depend on reactive reports from users.
Assign clear ownership with defined protocols. Revenue operations typically owns CRM data integrity, sales owns account and opportunity data, marketing owns campaign and engagement data. Each owner needs authority to reject bad data. When anomaly detection flags a 25% drop in daily contact imports, documented protocols should specify who gets alerted, investigation SLAs, and rollback procedures.
Integrate observability into workflows. Before campaigns launch, reporting, and before scaling, validate data readiness, data integrity and data reliability respectively. Track mean time to detection (MTTD) and mean time to resolution (MTTR) for data incidents. Improving these metrics is the goal of observability.
The foundation of revenue growth strategy is having a unified RevOps data infrastructure.
Why Closing the Data Observability Gap Is a Strategic Advantage
The data observability gap is not about systems going down, it is about broken data continuing to drive decisions undetected.
Fixing pipeline inefficiency is impossible if you can’t see that 30% of contact data is stale. Optimizing conversion is impossible when you don’t even know your lead scoring broke six weeks ago. And if you can’t quantify the revenue impact of current failures, you’ll never justify data quality investments.
For revenue leaders, the observability gap represents a fundamental strategic vulnerability: flying blind while believing you can see. Based on industry standards, data problems may affect between 20-30% of all operational data pipelines at any given moment, yet without causing any failure points. These problems go unnoticed for a long time, which means that decisions are being made based on inaccurate data.
Data maturity’s next step is not about having more data, using more tools, or creating additional dashboards. The focus should be on improving data visibility. Because targeting depends on accurate data, prioritization depends on timely data, and conversion depends on relevant data.
Organizations implementing comprehensive observability see measurable improvements. Full-stack observability reduces outage costs by 37% and mean time to recovery by 50%. Research shows 51% of organizations report achieving a 2-3x ROI on their observability spend.
Closing the data observability gap is the next step in data maturity and the most underdiscussed competitive advantage in modern GTM.












