

The GTM data latency problem is not about wrong data, it’s about late data. Most organizations assume poor decisions trace back to inaccurate information. The real culprit is timing: intelligence that arrives after the window to act has already closed.
This timing problem is a hidden risk in Revenue Operations and Go-To-Market systems. Their analytics focus more on deep reporting rather than how quickly data can be delivered. Monthly pipeline reviews inform weekly execution calls. SDR teams receive intent signals after buying windows have cooled. Forecasting models reflect historical snapshots instead of live pipeline movement.
A 2024 RevOps survey found that 57% of critical GTM decisions are made before fresh data is even available. A 2025 benchmark of 68 revenue-focused organizations found that 79% of revenue-critical systems were still fed by batch-based pipelines, with a median end-to-end latency of 26 hours.
In B2B environments where buyers move from anonymous research to vendor shortlists in days, a 26-hour intelligence lag is not a minor inefficiency. It is a structural competitive disadvantage.
Why the GTM Data Latency Problem Is Now a Revenue Liability
Modern B2B buyer behavior moves faster than legacy reporting cycles were built to handle. Buying committees form and evolve rapidly. Budget priorities shift within weeks. Leadership changes open or close pipeline opportunities with no advance notice.
A 2024 study of high-intent accounts found that 54% of accounts signaling strong buying intent converted to meetings within 48 hours, and 78% showed no active signal beyond the 72-hour mark. GTM teams often act on outdated data, one to three days old, which means they target buyers who’ve moved on and rely on signals that have already expired.
Research by HBR shows that firms responding to inbound leads within an hour are seven times more likely to qualify those opportunities than those who take even a little longer. Still, most revenue stacks take 8 to 24 hours to provide insights. This delay can be a real issue. For example, a lead generated on Monday might not reach a sales rep until Wednesday, accumulating about 54 hours of delay. Since the chances of converting a lead fall off sharply after just an hour, that backlog turns into missed opportunities.
You can read more about data prioritization in B2B here.
Four Structural Sources of Data Latency in GTM Stacks
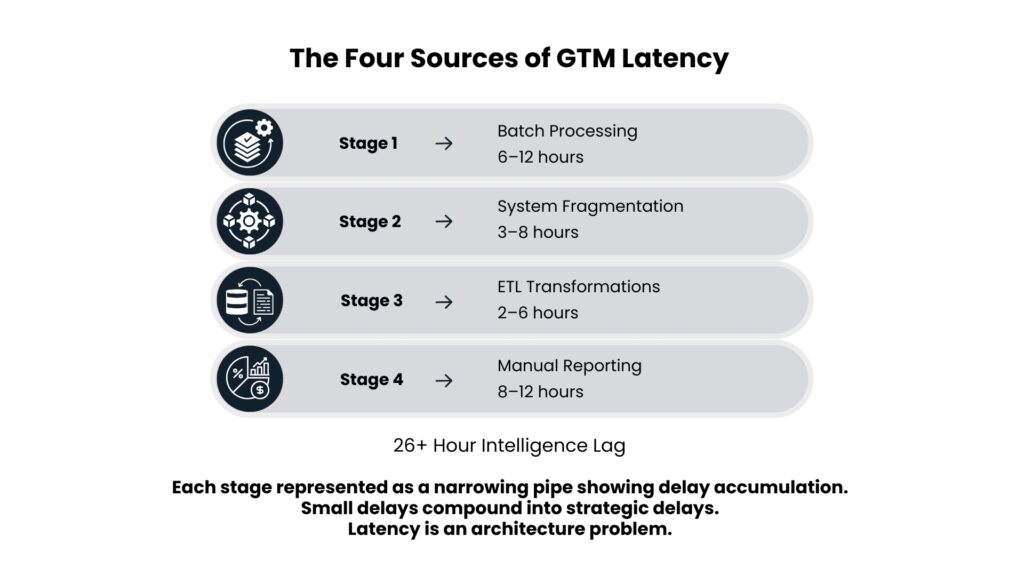
The GTM data latency problem is not a single bottleneck. It compounds across four interconnected layers.
Batch Processing Pipelines
Most enterprise data warehouses still run on batch-oriented ETL cycles. Raw events are grouped and processed on hourly or daily schedules. Even when event collection happens in real time, batch transformation introduces hours of processing lag before any signal reaches an operational system. A 2025 audit found the median end-to-end latency across these systems at 26 hours.
Fragmented System Architecture
On average, businesses use 8 to 12 tools for their revenue stack. When a high-intent signal comes in, it needs to go through web analytics, marketing automation, a data warehouse, enrichment services, a scoring engine, a CRM, and a sales engagement platform. With each step taking 30 to 90 minutes, the urgent lead from the start of the day can become outdated by hours. And it gets worse – integration issues don’t just add time; they multiply delays.
ETL Transformation Delays
Transformation logic introduces additional lag through complex joins between Salesforce, CDPs, enrichment providers, and intent platforms. Late-updating reference tables and territory mappings create a patchwork state where some attributes are current and others are weeks old. This partial staleness is operationally worse than plain latency because it produces misleading intelligence rather than a visible gap.
Manual Reporting Cycles
A significant share of business intelligence still runs through human-generated analysis. Analysts export data, clean it in spreadsheets, and prepare slides for leadership. This cycle often adds 8 to 12 hours on top of system latency. One 2025 case study found that 41% of urgent pipeline and forecasting requests were not completed until two calendar days after the triggering event.
Revenue Consequences of Unresolved Data Latency in GTM Systems
Each of the following consequences traces directly to unresolved data latency in GTM systems.
Missed Buyer Windows
High-intent signals lose conversion value rapidly. A 48-hour delay in routing intent-driven accounts was estimated in one RevOps stack to cost 19% of potential pipeline from that cohort. Organizations technically possess the right intelligence. They operationally fail to act before the opportunity expires.
Structurally Inaccurate Forecasting
A 2025 RevOps benchmark found that models updated once per week had 16 to 22% higher error rates compared to models ingesting data within 12 hours. Models trained on daily snapshots overestimated close rates by an average of 13% because they lagged short-cycle velocity changes. These errors cascade into quota allocation, territory design, and budget decisions built on a pipeline state that no longer exists.
Operational Waste Across GTM Teams
Stale data forces reactive behavior. Sales reps spend hours researching accounts based on last week’s profiles, unaware of executive changes or competitive tool adoptions that occurred 48 hours prior. Customer success teams identify churn risk after intervention windows narrow. The waste is invisible in individual workflows but accumulates into measurable capacity loss across the organization.
Framework: The Intelligence Velocity Matrix
Not all data requires real-time processing. Solving the GTM data latency problem starts with identifying where latency directly degrades revenue outcomes and where batch processing remains sufficient.
A practical model evaluates each data flow across two dimensions: decision frequency and value decay rate.
Tier 1: Real-Time Critical. High frequency plus fast decay. Examples include inbound lead routing, buying intent signals, and product trial engagement. These require sub-15-minute latency and justify event-driven streaming infrastructure.
Tier 2: Near-Real-Time Operational. High frequency plus slower decay. Examples include account-level engagement scoring and contact enrichment. These benefit from 15 to 60-minute refresh cycles through incremental processing or change data capture.
Tier 3: Strategic Analytical. Low frequency, used for planning. Examples include quarterly business reviews and territory design. Daily or weekly batch processing is appropriate here.
This tiering prevents over-engineering and aligns infrastructure cost with revenue impact.
How to Build a Low-Latency GTM Intelligence System
Event-Driven Architectures for Critical Signals
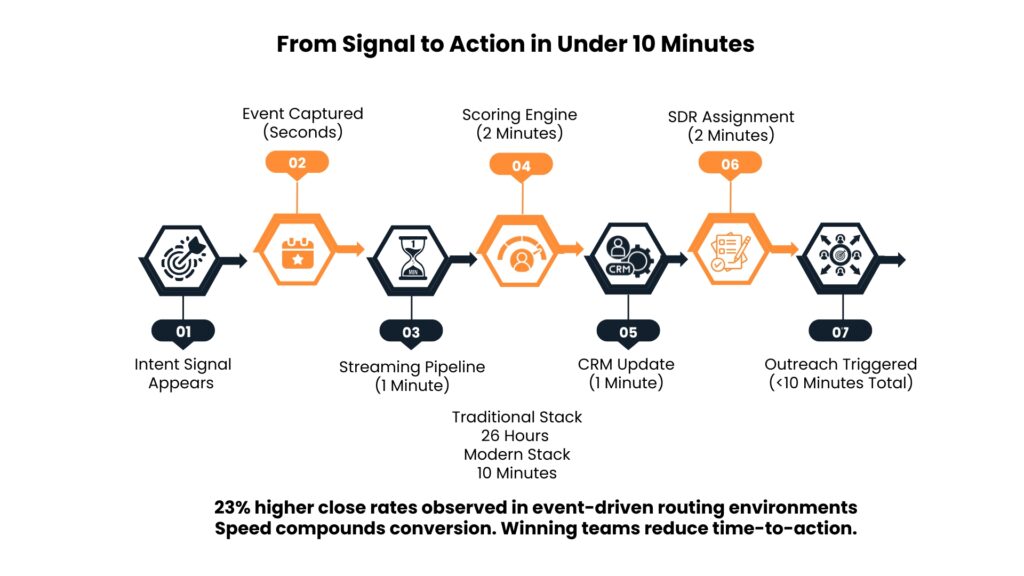
Instead of waiting for those scheduled syncs, event-driven architectures catch signals right when they happen and instantly send them off. So, when a prospect visits a pricing page or hits a product usage milestone, an event record gets sent through something like Apache Kafka. Then, downstream systems can grab that info in seconds, not hours. In one case, a RevOps team used this method to assign enterprise accounts with sudden interest spikes to a dedicated SDR pod within minutes. This led to a 23% higher close rate compared to accounts processed through batch pipelines.
Incremental Processing as a Middle Path
For organizations not quite ready for full streaming, incremental processing offers major upgrades without an extensive revamp. Rather than refreshing whole datasets nightly, systems now update only what’s changed, every 5 to 15 minutes. Plus, platforms like Snowflake, Databricks, and BigQuery make this easy via change data capture and materialized views. So, a firm dealing with 100,000 daily CRM updates could go from that big 24-hour lag to just 15 minutes – all with minor infra tweaks.
Automated Alerting and Decision Triggers
Low latency only matters when paired with automation. Top performers link smarts right into their workflows, sending real-time notifications for intent spikes, kicking off plays when pipelines lag, and routing stuff automatically based on fit. Advanced setups take it up a notch too. They can pause campaigns or switch to retargeting when conversions slow down, and adjust the timing and channels based on actual engagement.
Practical Recommendations for RevOps Leaders
First, audit the current latency and then make those infrastructure changes. Document when data hits source systems, when it gets to GTM platforms, and when decision-makers see it. You’d be surprised how many delays are lurking around that nobody tracked before.
So rank the high-value data flows first. Give each one a score based on decision criticality, market dynamics, and latency tolerance. After that, focus on upgrading streaming or incremental processing for the top two to four data flows. Also, aim to get latency down from 24 hours to less than an hour first. Then, you can target reducing times from one hour to under one minute.
Set clear goals for how fresh your data needs to be. For top performers, key revenue signals should hit action inlets in under 10 minutes, lead scoring updates within 30, and opportunity data sync’d up in an hour. Companies acting ten times slower are working with stale info that could mislead decision-making.
Also, keep an eye on how long it takes for an event to affect sales actions. Treat end-to-end latency as a crucial performance indicator right next to pipeline and conversion rates.
Conclusion: Speed Determines Whether Insights Have Value
In modern GTM systems, accurate information alone is no longer sufficient. Timing determines whether intelligence creates competitive advantage or becomes operational hindsight.
The future of B2B intelligence will not be defined solely by data quality or data volume. Closing the GTM data latency gap will define which organizations convert signals into decisions.
Insights that arrive too late are, in every practical sense, indistinguishable from no insights at all.















