
Your sales team tracks intent data from six providers. Your CRM pulls buyer signals from twelve sources. You spent $150,000 on data subscriptions this year. Yet when your SDRs reach out to high-intent accounts, 68% of conversations go nowhere. You are experiencing signal inflation, the paradox where B2B intent data from multiple sources dilutes predictive accuracy instead of improving it.
Forrester’s Q1 2025 Intent Data Providers Wave found that 50% of companies leveraging B2B intent data report too many false positives. Forrester’s comprehensive evaluation of B2B intent data providers revealed that signal quality, not volume, determines effectiveness, with leading vendors focusing on precision over broad coverage.
When half your hot accounts turn out to be researchers or competitors, the problem is not a lack of data. It’s too much undifferentiated noise drowning genuine signals in B2B intent data.
When More B2B Intent Data Becomes the Problem
The B2B intent data market exploded over the past five years, creating unprecedented signal noise. With 70-100% of B2B marketing and sales teams now using third-party intent data, according to 2024 industry surveys, the same signals trigger alerts for hundreds of vendors simultaneously. When a prospect shows content consumption activity, they receive 36 or more vendor outreaches within two weeks, per Demand Gen Report’s 2024 Buyer Behavior Survey. The feeding frenzy creates the exact opposite of competitive advantage.
Recent predictive modeling research confirms that simple models using 10 carefully selected data series often outperform complex models ingesting hundreds of variables. The lesson translates directly to B2B sales intelligence: disciplined signal selection beats indiscriminate accumulation. As global data volume approaches 175 zettabytes, the challenge is no longer a shortage of information. It is the explosion of noise.
Four Mechanisms Driving B2B Intent Data Inflation
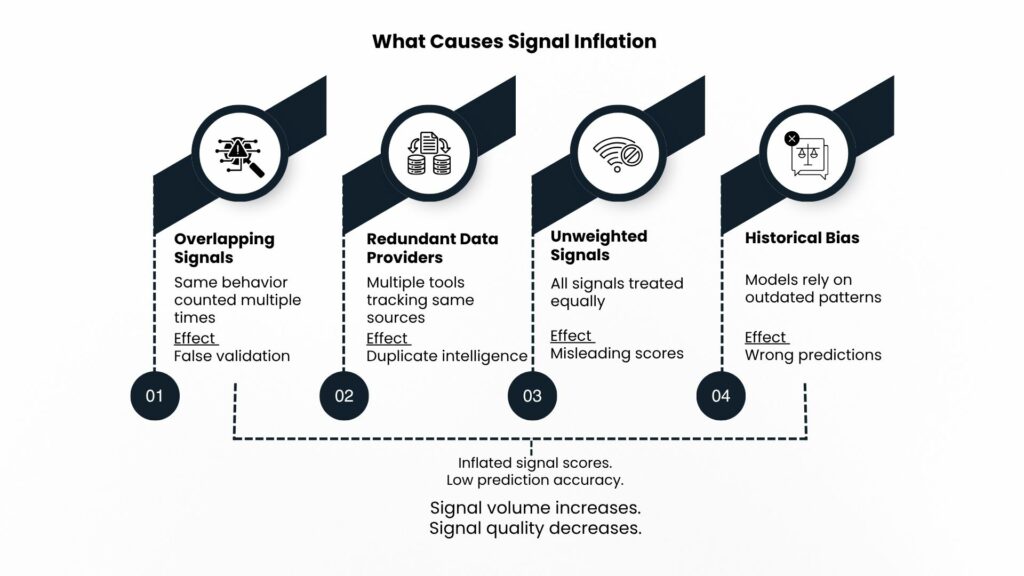
Signal inflation in B2B intent data stems from four predictable mechanisms that compound inaccuracy.
Overlapping Indicators
A prospect downloads a whitepaper tracked by one intent provider. That same download gets counted by a second provider monitoring the same publisher. Three signals from three vendors describe one behavioral event. Teams mistake redundant data for validation when they are seeing echo chamber effects. When these signals enter models without adjustment, the system overestimates buyer intent and inflates account scores.
Redundant Data Providers
Most third-party intent platforms source signals from overlapping pools: bidstream data, B2B publisher cooperatives, and the same handful of review sites. When providers claim to track trillions of intent signals, they are often tracking many of the same signals repackaged with different scoring. Subscribing to multiple vendors without de-duplication creates weighted repetition, not additional intelligence.
Unweighted Signals
A CFO visiting your pricing page three times in a week receives the same intent score as an intern downloading an educational whitepaper. Without weighting that accounts for role, recency, and engagement depth, raw signal volume creates false confidence. At Packed Data, this is exactly why the approach centers on a minimum viable signal framework: identifying the three to five core triggers that actually correlate with revenue rather than treating all activity as equally meaningful.
Historical Bias in Models
Many predictive scoring systems train on past closed deals, creating self-reinforcing cycles. If historical data shows that accounts with high content consumption converted well, the model keeps surfacing similar accounts, even as buyer behavior evolves. NetLine’s 2024 B2B content consumption report found that 25% of intent surges led to no meaningful buying activity within six months. One in four high-confidence signals produces nothing. That is not prediction. It is expensive guesswork dressed up with dashboards.
What Over-Signaling Actually Costs You
Poor B2B intent data quality creates cascading costs across sales operations.
False Positives
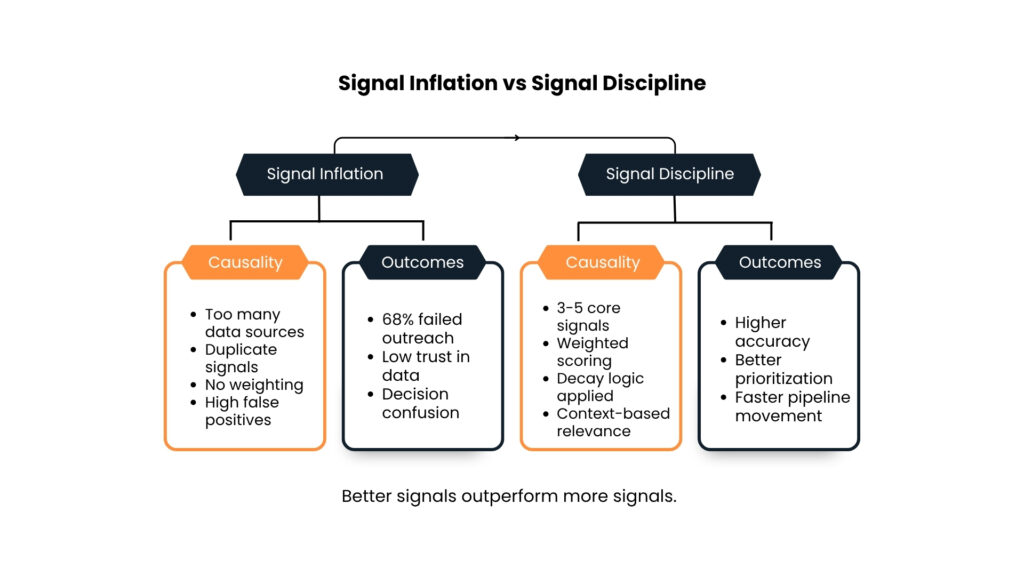
Over-signaled models surface hundreds of leads showing intent without actual buying power or technical fit. According to research on B2B intent data effectiveness, 87% of B2B teams deal with unreliable intent signals, and only 26% of those signals turn into real opportunities. SDRs chase accounts that were never in-market. Pipeline quality collapses. Credibility erodes with both buyers and the sales team itself.
Model Overfitting
When too many variables enter predictive scoring without proper regularization, models fit noise rather than genuine patterns. They achieve impressive accuracy on historical data while failing on new prospects. One SaaS organization reduced its active signals from 60 to 12 and saw scoring accuracy rise from 55% to 88%. The fewer, better-chosen signals produced a model that actually worked in the field.
Rep Distrust and Decision Paralysis
When sales teams watch high-scoring accounts go cold repeatedly, they stop trusting the intelligence system. Manual overrides reach 50% at organizations where signal quality has degraded, per Gartner research. The expensive data infrastructure becomes shelfware. At the executive level, contradictory recommendations from competing providers create a fog of war. Teams hold meetings to debate which prediction to trust. Forrester estimates decision paralysis from signal overload reduces pipeline velocity by 20%.
Building B2B Intent Data Discipline
Signal Hierarchy Frameworks
Build a hierarchy that weights indicators by predictive power. Packed Data organizes signals into three tiers.
Tier-1 covers high-signal intent and technographic data: the strongest indicators of buying readiness.
Tier-2 covers supporting firmographic context.
Tier-3 covers general behavioral signals used for background awareness only. Direct engagement, such as demo requests and pricing page visits, outweighs passive signals. This hierarchy must be explicit and consistently applied.
Decay Weighting
A technographic shift from six months ago is cold. A website visit from four hours ago is not. Effective implementations apply exponential decay: recent signals carry maximum weight, last week’s signals contribute partial influence, and anything beyond 60 days drops from active scoring entirely. Packed Data’s real-time enrichment model is built around this principle, ensuring stale data points do not artificially inflate account priority scores.
Contextual Relevance Scoring
A high-intent signal from a company with the wrong technology stack is a distraction. By integrating ICP analytics directly into the scoring model, signals are amplified only when they occur within a high-fit context. Multiple technical roles engaging integration documentation suggests active evaluation. General business content consumption suggests early awareness. These are not equivalent, and your model should not treat them as though they are.
Human-in-the-Loop Validation
Automated models catch scale. Humans catch context. Regular feedback loops where sales reps flag poor leads allow models to learn the difference between a real signal and noise specific to your industry. Hybrid approaches combining AI predictions with expert validation consistently outperform either pure automation or purely manual analysis. A rep’s ability to downvote a lead teaches the system what generic intent actually looks like in your market.
What Signal Discipline Delivers
Higher trust in intelligence: When scores consistently align with outcomes, sales teams use them. Win rates on accounts targeted through disciplined intelligence are double those from generic outbound prospecting. Trust becomes self-reinforcing as successful conversions refine models.
Fewer false alerts: Teams using intent data strategically achieve 2.5x improvement in engagement rates compared to baseline campaigns. Buyers receive outreach only when strong signal convergence suggests genuine buying activity.
Cleaner prioritization: Organizations with disciplined signal frameworks report higher pipeline-to-close conversion rates, faster deal velocity, and larger average deal sizes. One fintech organization applying signal discipline with Packed Data’s weighted intent and technographic data saw ARR increase by $5.1 million and customer acquisition cost drop by 27%.
Sharper Intent Signals, Better Predictions
The competitive advantage in B2B sales intelligence is not who accumulates the most signals. It is who filters most effectively, weights most accurately, and maintains the discipline to ignore the majority of data in pursuit of the minority that actually predicts outcomes.
At Packed Data, the philosophy is that data for the sake of data is a liability. The goal is insight density: pre-filtered account intelligence and real-time company insights designed to simplify decision-making. CRM integrations built on this model surface the signal that matters, ensuring AI-driven prioritization rests on high-fidelity data rather than inflated noise.
Audit your current signal stack. Identify which sources overlap. Build a decay model. Establish a signal hierarchy. The organizations that sharpen their signals will outpredict and outperform those still collecting everything and trusting nothing.















