

Identity resolution B2B is the difference between clarity and chaos in your revenue systems. One company exists as five separate records in your CRM. Three more live in your marketing automation platform. Another dozen sit scattered across enrichment and intent tools. Each version shows different domains, employee counts, and activity histories. Sales treats them as distinct accounts. Marketing segments them inconsistently. Leadership makes decisions on pipeline data that counts the same revenue multiple times. This identity resolution problem fragments your entire go-to-market motion.
It costs B2B organizations an average of $12.9 million annually in poor data quality alone, according to Gartner. The typical organization has an overlap rate of 20-30% in its accounts file. For a mid-sized business, this results in a waste of $1.8 million of its potential pipeline every year.
It’s more than just duplication. In cases where your data system doesn’t even recognize what one account is, all the downstream GTM functions become shaky. Targeting goes haywire. Prioritization becomes an issue. Attribution becomes difficult. One retail organization that utilized identity resolution through artificial intelligence technology found out about 3.5 million email addresses they could not have accessed before.
What Identity Resolution B2B Actually Means
Identity resolution is the process of linking fragmented records into a unified, accurate representation of an entity. In B2B systems, this applies across three critical layers.
The company-level identity refers to linking identities between CRM, marketing, and data platforms. We need to link ‘IBM,’ ‘International Business Machines,’ ‘ibm.com,’ and ‘ibm.co.uk’ to one master identity. In the absence of such linking, we will see all four identities as individual entities and treat each separately.
Identity management at the contact level refers to establishing the same identity despite using different email addresses or playing different roles. An individual who uses a personal email address to participate in a webinar but uses an official email to submit a request for product demonstration would have two contacts.
Organizational hierarchies represent the most complex layer. Parent companies, subsidiaries, business units, and regional divisions must connect through a corporate family tree. A sales team targeting what appears to be a small regional office may miss that it belongs to a global enterprise with centralized buying power.
Why Identity Resolution Fails in B2B Data Systems
Identity fragmentation is structural, not accidental. Companies operate across multiple domains: regional variations (.com, .co.uk, .de), product-specific domains, and acquired brand domains. Research shows 68% of accounts maintain two or more active domains. Most systems treat domains as unique identifiers, creating false separation of the same entity.
Naming discrepancies further add to the challenge. “Accenture Ltd.”, “Accenture,” and “Accenture PLC” all describe one company, yet vague naming differences yield a 42% mismatch rate with conventional matching techniques. Legal endings, abbreviation practices, and different spellings undermine deterministic matching techniques.
The real challenge stems from data sources, which represent the most substantial structural challenge. CRMs, marketing automation software companies, enrichment tools, and intent data providers each prioritize their unique data structures. ZoomInfo, 6sense, and Clearbit bring unique ID systems that never fully sync. When data from multiple sources combine without resolution, duplication increases. Cookie loss and remote work have accelerated this fragmentation by eliminating IP-based office matching, which previously helped consolidate identities.
Organizational changes introduce identity drift. Mergers, acquisitions, rebranding, and restructuring mean existing records no longer reflect reality. Without continuous resolution, static databases cannot keep pace.
The Revenue Impact of Poor Identity Resolution
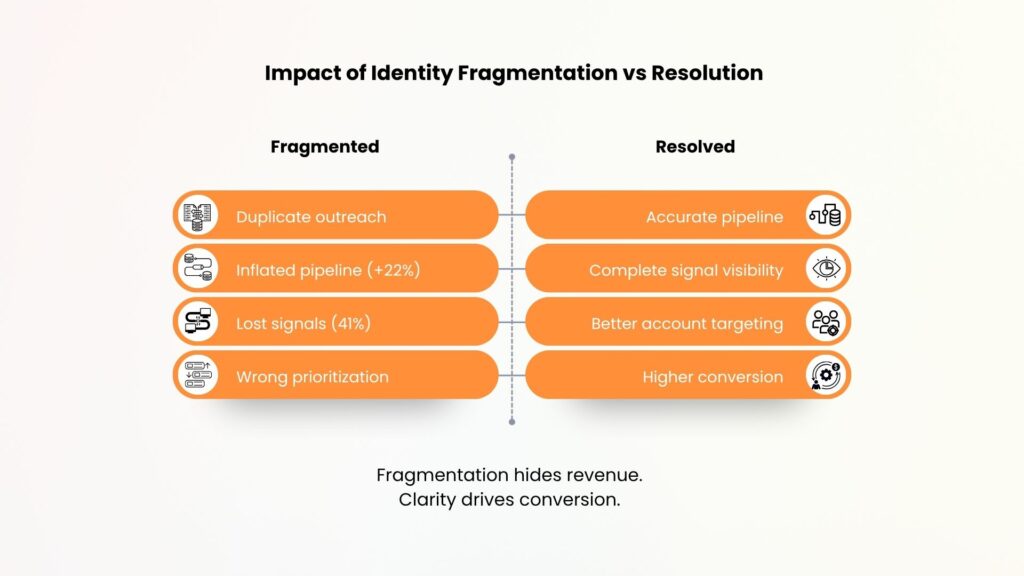
The same account appearing multiple times creates compounding inefficiencies across the revenue engine. Duplicate outreach occurs when SDRs unknowingly contact the same company through different records. One SaaS company running ABM discovered 28% of their accounts were duplicates, resulting in triple outreach to the same contacts. This drove a 41% complaint rate from VP-level buyers and created $910,000 in annual pipeline waste.
Inaccurate reporting distorts every metric that drives strategic decisions. Pipeline appears to be 22% larger than reality. Account coverage gets overstated. Attribution breaks when a marketing campaign drives leads to “Subsidiary A” but the deal closes under “Parent B,” showing zero ROI for profitable campaigns. One technology firm with 18% duplicate accounts discovered $1.4 million in reporting errors and 27% incorrect account prioritization.
Poor account visibility prevents effective selling. When buying committee members spread across three duplicate records, engagement signals fragment. Intent data showing activity on an alias goes unnoticed. A contact engaging with a whitepaper appears cold, while four other executives on a duplicate record actively evaluate pricing. Cross-sell opportunities within the same ultimate parent get missed entirely.
Intent and prioritization signals depend on accurate identity mapping. If identity fragments, signals attach to wrong records. Prioritization models become unreliable. High-value accounts slip through. According to industry data, 41% of buying signals get lost to siloed subsidiary activity that never connects to master accounts.
Identity Resolution B2B Techniques That Scale
Effective resolution requires multiple techniques working together. Domain-based matching uses primary web domains as unique identifiers, achieving 92% recall on domain variants through WHOIS clustering and subdomain normalization. This method provides high precision but fails when companies use multiple domains or generic email providers.
Probabilistic matching applies statistical methods to link records with high likelihood of belonging to the same entity, even without exact matches. The Fellegi-Sunter model calculates match probability across multiple attributes: company name similarity, location matching, and firmographic alignment. This attains 89% precision and 92% recall, though meticulous calibration is needed to prevent false merging.
Hierarchical linking constructs parent-subsidiary linkages along the company lineage. External third-party firmographics from sources such as Dun & Bradstreet map regional subsidiaries to their ultimate parents without manual intervention. This enables account-level visibility and strategic targeting but remains complex to maintain as organizations evolve.
Graph-based entity resolution treats accounts as connected networks rather than isolated records. Neo4j and similar graph databases link entities through shared domains, contacts, and activities, achieving 96% precision. This method excels at uncovering hidden relationships but scales more slowly than deterministic approaches.
The Resolution Implementation Framework
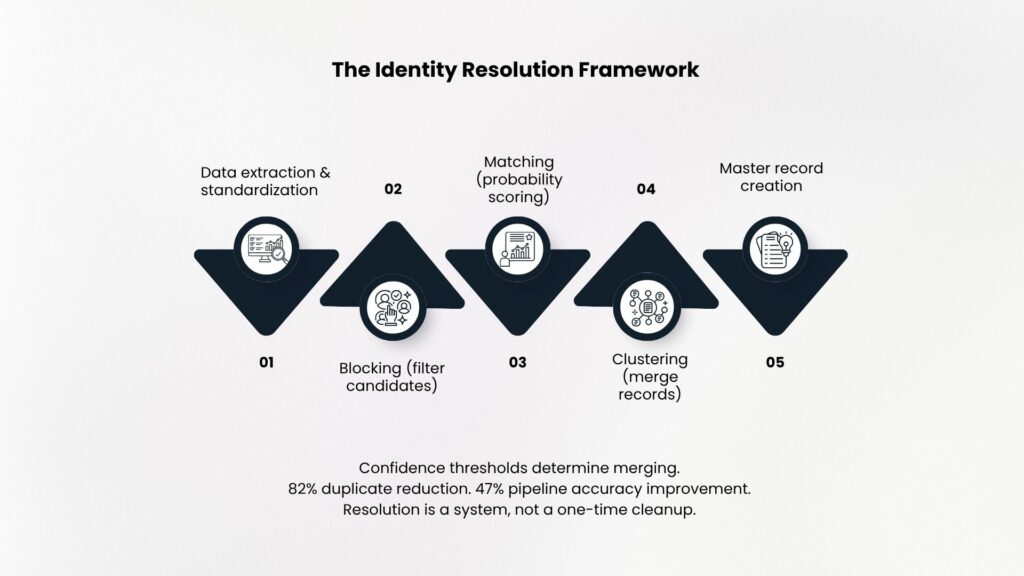
Unification of identities can be achieved through an organized, four-step procedure. Extraction standardizes variants through processes such as converting domains into lowercase, standardizing company names, and cleaning addresses. Blocking pre-filtering helps to filter candidates using common domain bases and geographic proximity. This step greatly decreases pairwise comparisons from millions to thousands.
Pairwise matching computes probability scores for candidates matched together. Weighted importance is assigned based on features such as domain base match (0.4), name fuzzy match (0.3), address match (0.2), and geographic proximity (0.1). Matching pairs above 0.85 confidence are automatically merged, whereas those with scores within 0.75 to 0.85 are manually reviewed.
Records associated with clustering were combined to form master records with the help of graph algorithms. The results from one RevOps team that used this model showed an 82% decrease in duplication and a 47% increase in pipeline accuracy.
Strict threshold scores (0.92) lead to 2% false positives but fail to identify some duplicates, whereas liberal threshold scores (0.82) capture more duplicates yet yield 12% false positives.
Practical Recommendations for RevOps Teams
Implementing identity resolution B2B starts with the discovery audit. Export 10,000 contacts from your CRM and enrichment software. The fragmentation rate can be calculated by finding out how many contacts have same or similar domain addresses or same names.
Domain clustering should be implemented as your first step to solve the problem. The use of custom Python scripts that leverage WHOIS information along with fuzzy matching will help to identify around 30% to 40% of duplicate data in two weeks’ time. The Dedupe open-source software is helpful in identifying name and address variations by setting confidence scores.
Build hierarchical resolution for enterprise accounts. Manually map parent-subsidiary relationships for your top 100 accounts. For the long tail, integrate automated hierarchy intelligence from specialized data providers that track corporate structure changes in real time.
Establish continuous synchronization across systems. Identity resolution is not a one-time project. Weekly monitoring should track duplicate rates below 3%, merge accuracy above 95%, and signal alignment across platforms. A Forrester study found organizations achieved 226% ROI over three years through systematic identity resolution, with $19.7 million in net present value for a composite organization.
Conclusion: Clarity Begins with Identity
Most B2B firms emphasize the gathering of more data, the enrichment of current data, and better targeting. All these activities offer little benefit without proper identity. It is impossible to trust data, interpret signals, or optimize decisions without a clear understanding of identity.
The competitive advantage in modern GTM systems comes not from having more records but from knowing which records represent the same reality. Resolution transforms fragmented accounts into unified entities. It converts data accumulation into identity intelligence. It replaces isolated systems with connected visibility.
According to MIT Technology Review, 78% of organizations do not feel ready to implement AI tools, with fragmented customer data as the primary barrier. B2B identity resolution removes that barrier. It serves as a basis for more advanced and effective account-based marketing, attribution analysis, and predictive modeling.
The shift required is foundational: moving from scattered records to cohesive identities, from redundant outreach to purposeful engagement, and from deceptive dashboards to reliable insights. True data clarity starts with clear identity. Without it, nothing else holds together.









